3 minutes
Benchmarking .NET CSV Parsers
Introduction
As part of my new job, I am around csv files quite a lot. One of the tasks internally was to design and create a package which read common csv files for the company, as a NuGet package, so it could be used across internal company tools.
Now, instead of writing an entire CSV parser, I decided to use an existing package, with a small intermediary layer which implemented business-specific details, such as models, and simpler interface.
The two main contesters were:
So the next step was to do some benchmarking.
Benchmark Setup
You can find the benchmarking code here.
Dataset
The data I used is Historical stock data for all current S&P 500 companies, which contains 600,000 stock records.
Considerations
These packages use reflection under the hood most of the time, to get information from the models such as:
- Field Order: Defines which csv column index matches with which property in a given model
- Custom Converters: For complex objects, a custom converter can be used to convert from string to object, and back to string.
- Custom Titles: For writing back to csv files, sometimes you want the headers to be different from the property names.
… which means that the constructor for the engine can be quite costly (because reflection in .NET is costly). To factor this in, I constructed the benchmarks to cache the engine where possible.
Benchmarks
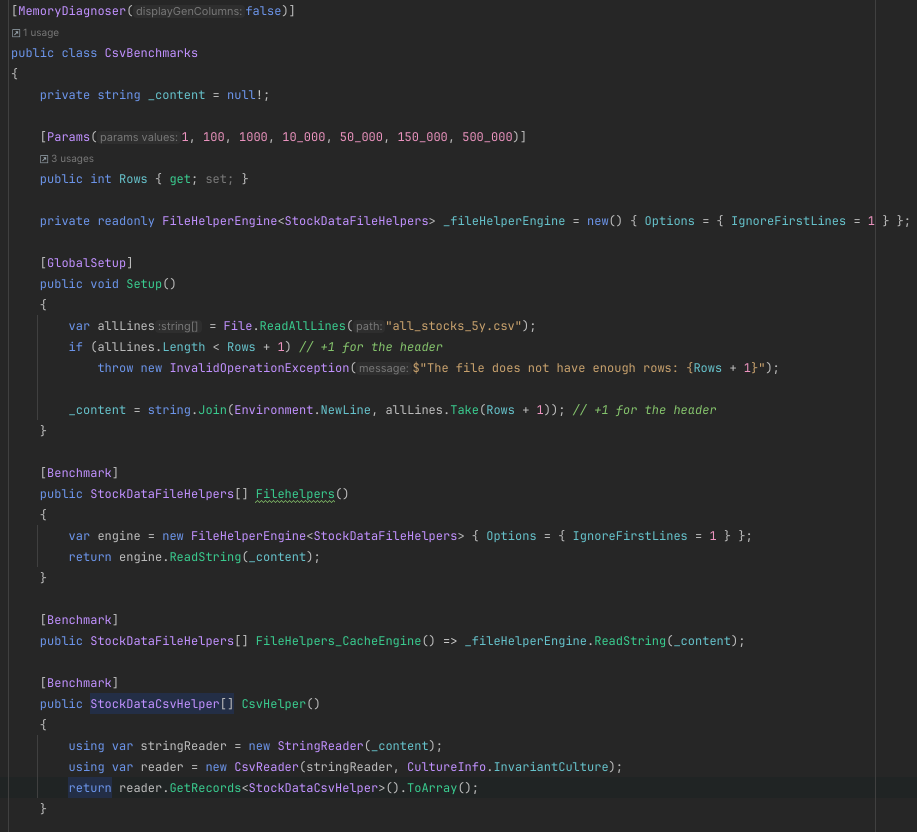
We’re testing on reading of 1, 100, 10,000, 50,000, 150,000 and 500,000 rows, which should hopefully show the overhead of both engines, and how the performance changes with size.
Unfortunatly, CsvHelper doesn’t provide a way of caching the engine. Once a stream has been read, the CsvHelper object can’t be used again :(
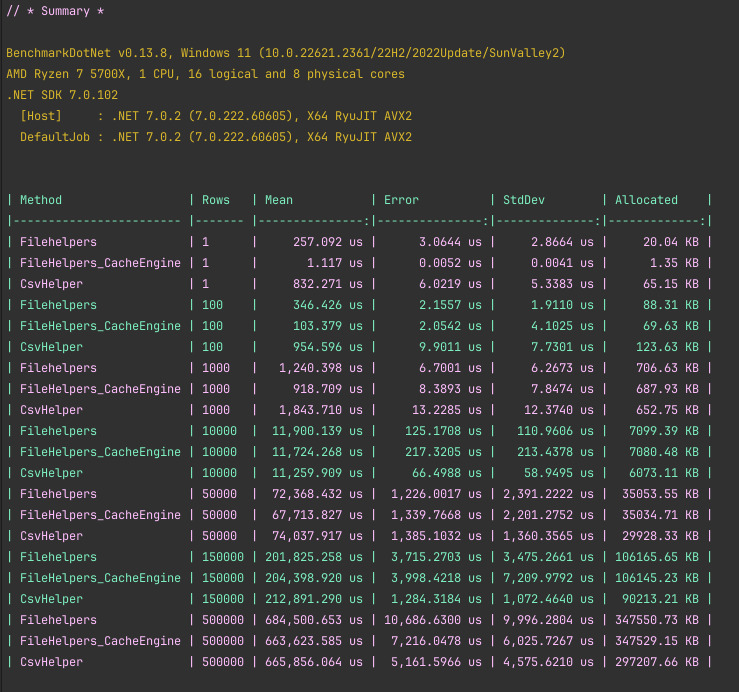
Benchmark Results
Conclusion
Using these numbers, a number of conclusions can be made:
- FileHelpers is create for small datasets, with up to 3x performance and memory.
- Performance across both packages are very similar with large datasets.
- For FileHelpers, cache your engine if you can.
I would have liked to benchmark all of this on .NET 8 too, however due to a bug in .NET 8 RC1, I will have to wait for RC2 to fully test performance. I expect that .NET 8 will be faster, but it will be interesting to see by how much.
Other comparisons
Personally, I have found FileHelpers to be all-round better than CsvHelper. This is due to how simple it is to
The benefits of CsvHelper over FileHelpers are:
- CsvHelper has async parsing, which would be great for use in APIs.
GetRecordsstreams results back viaIEnumerable<T>, which is great for large datasets. FileHelper returnsT[], allocating everything into memory 👎.
The benefits of FileHelpers over CsvHelper are:
- Simpler API interface
- Seemingly more control over errors when parsing